Среднее квадратическое отклонение имеет размерность. Геометрическая простая
$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
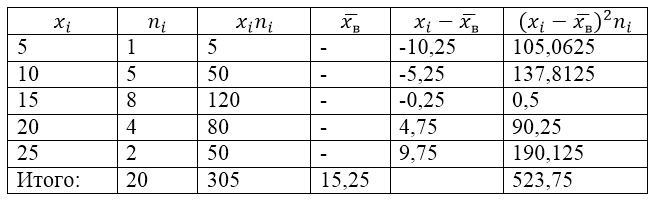
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом . В то же время не все так плохо. При увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной. Поэтому при работе с большими размерами выборок можно использовать формулу выше.
Язык знаков полезно перевести на язык слов. Получится, что дисперсия — это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Разгадка заключается всего в трех словах.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который необходим для других видов статистического анализа. У нее даже единицы измерения нормальной нет. Судя по формуле, это квадрат единицы измерения исходных данных. Без бутылки, как говорится, не разберешься.
{module 111}
Дабы вернуть дисперсию в реальность, то есть использовать в более приземленных целей, из нее извлекают квадратный корень. Получается так называемое среднеквадратичное отклонение (СКО) . Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквы). Формула стандартного отклонения имеет вид:
![]()
Для получения этого показателя по выборке используют формулу:

Как и с дисперсией, есть и немного другой вариант расчета . Но с ростом выборки разница исчезает.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Но и этот показатель в чистом виде не очень информативен, так как в нем заложено слишком много промежуточных расчетов, которые сбивают с толку (отклонение, в квадрат, сумма, среднее, корень). Тем не менее, со среднеквадратичным отклонением уже можно работать непосредственно, потому что свойства данного показателя хорошо изучены и известны. К примеру, есть такое правило трех сигм , которое гласит, что у данных 997 значений из 1000 находятся в пределах ±3 сигмы от средней арифметической. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Коэффициент вариации
Среднее квадратическое отклонение дает абсолютную оценку меры разброса. Поэтому чтобы понять, насколько разброс велик относительно самих значений (т.е. независимо от их масштаба), требуется относительный показатель. Такой показатель называется коэффициентом вариации и рассчитывается по следующей формуле:
Коэффициент вариации измеряется в процентах (если умножить на 100%). По этому показателю можно сравнивать самых разных явлений независимо от их масштаба и единиц измерения. Данный факт и делает коэффициент вариации столь популярным.
В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. Мне здесь трудно что-то прокомментировать. Не знаю, кто и почему так определил, но это считается аксиомой.
Чувствую, что я увлекся сухой теорией и нужно привести что-то наглядное и образное. С другой стороны все показатели вариации описывают примерно одно и то же, только рассчитываются по-разному. Поэтому разнообразием примеров блеснуть трудно, Отличаться могут лишь значения показателей, но не их суть. Вот и сравним, как отличаются значения различных показателей вариации для одной и той же совокупности данных. Возьмем пример с расчетом среднего линейного отклонения (из ). Вот исходные данные:

И график для напоминания.

По этим данным рассчитаем различные показатели вариации.
Среднее значение – это обычная средняя арифметическая.
Размах вариации – разница между максимумом и минимумом:
Среднее линейное отклонение считается по формуле:
Стандартное отклонение:
Расчет сведем в табличку.

Как видно, среднее линейное и среднеквадратичное отклонение дают похожие значения степени вариации данных. Дисперсия – это сигма в квадрате, поэтому она всегда будет относительно большим числом, что, собственно, ни о чем не говорит. Размах вариации – это разница между крайними значениями и может говорить о многом.
Подведем некоторые итоги.
Вариация показателя отражает изменчивость процесса или явления. Ее степень может измеряться с помощью нескольких показателей.
1. Размах вариации – разница между максимумом и минимумом. Отражает диапазон возможных значений.
2. Среднее линейное отклонение – отражает среднее из абсолютных (по модулю) отклонений всех значений анализируемой совокупности от их средней величины.
3. Дисперсия – средний квадрат отклонений.
4. Среднеквадратичное отклонение – корень из дисперсии (среднего квадрата отклонений).
5. Коэффициент вариации – наиболее универсальный показатель, отражающий степень разброса значений независимо от их масштаба и единиц измерения. Коэффициент вариации измеряется в процентах и может быть использован для сравнения вариации различных процессов и явлений.
Таким образом, в статистическом анализе существует система показателей, отражающих однородность явлений и устойчивость процессов. Часто показатели вариации не имеют самостоятельного смысла и используются для дальнейшего анализа данных (расчет доверительных интервалов
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
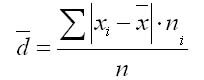
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Х i - случайные (текущие) величины;
X̅ – среднее значение случайных величин по выборке, рассчитывается по формуле:

Итак, дисперсия - это средний квадрат отклонений . То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат , складывается и затем делится на количество значений в данной совокупности.
Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую.
Разгадка магического слова «дисперсия» заключается всего в этих трех словах: средний – квадрат – отклонений.
Среднее квадратичное отклонение (СКО)
Извлекая из дисперсии квадратный корень, получаем, так называемое «среднеквадратичное отклонение». Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквыσ .). Формула среднего квадратичного отклонения имеет вид:
Итак, дисперсия – это сигма в квадрате, или – среднее квадратичное отклонение в квадрате.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеивания данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Размах вариации – это разница между крайними значениями. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Поэтому в методах статистической обработки данных в оценках объектов недвижимости в зависимости от необходимой точности поставленной задачи используют правило двух или трех сигм.
Для сравнения правила двух сигм и правила трех сигм используем формулу Лапласа:
![]() Ф - Ф ,
Ф - Ф ,
где Ф(x) – функция Лапласа;
Минимальное значение
s = значение сигмы (среднее квадратичное отклонение)
a = среднее значение
В этом случае используется частный вид формулы Лапласа когда границы α и β значений случайной величины X равно отстоят от центра распределения a = M(X) на некоторую величину d: a = a-d, b = a+d.
 Или
Или
  (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3). (1)
Формула (1) определяет вероятность заданного отклонения d случайной величины X с нормальным законом распределения от ее математического ожидания М(X) = a.
Если в формуле (1) принять последовательно d = 2s и d = 3s, то получим:
(2),
(3).
|
Правило двух сигм
Почти достоверно (с доверительной вероятностью 0,954) можно утверждать, что все значения случайной величины X с нормальным законом распределения отклоняются от ее математического ожидания M(X) = a на величину, не большую 2s (двух средних квадратических отклонений). Доверительной вероятностью (Pд) называют вероятность событий, которые условно принимаются за достоверные (их вероятность близка к 1).
Проиллюстрируем правило двух сигм геометрически. На рис. 6 изображена кривая Гаусса с центром распределения а. Площадь, ограниченная всей кривой и осью Оx, равна 1 (100%), а площадь криволинейной трапеции между абсциссами а–2s и а+2s, согласно правилу двух сигм, равна 0,954 (95,4% от всей площади). Площадь заштрихованных участков равна 1-0,954 = 0,046 (»5% от всей площади). Эти участки называют критической областью значений случайной величины. Значения случайной величины, попадающие в критическую область, маловероятны и на практике условно принимаются за невозможные.

Вероятность условно невозможных значений называют уровнем значимости случайной величины. Уровень значимости связан с доверительной вероятностью формулой:
где q – уровень значимости, выраженный в процентах.
Правило трех сигм
При решении вопросов, требующих большей надежности, когда доверительную вероятность (Pд) принимают равной 0,997 (точнее - 0,9973), вместо правила двух сигм, согласно формуле (3), используют правило трех сигм.
Согласно правилу трех сигм при доверительной вероятности 0,9973 критической областью будет область значений признака вне интервала (а-3s, а+3s). Уровень значимости составляет 0,27%.
Другими словами, вероятность того, что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна 0,0027=1-0,9973. Это означает, что лишь в 0,27% случаев так может произойти. Такие события, исходя из принципа невозможности маловероятных событий, можно считать практически невозможными. Т.е. выборка высокоточная.
В этом и состоит сущность правила трех сигм:
Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания не превосходит утроенного среднего квадратического отклонения (СКО).
На практике правило трех сигм применяют так: если распределение изучаемой случайной величины неизвестно, но условие, указанное в приведенном правиле, выполняется, то есть основание предполагать, что изучаемая величина распределена нормально; в противном случае она не распределена нормально.
Уровень значимости принимают в зависимости от дозволенной степени риска и поставленной задачи. Для оценки недвижимости обычно принимается менее точная выборка, следуя правилу двух сигм.
Стандартное отклонение - классический индикатор изменчивости из описательной статистики.
Стандартное отклонение , среднеквадратичное отклонение, СКО, выборочное стандартное отклонение (англ. standard deviation, STD, STDev) - очень распространенный показатель рассеяния в описательной статистике. Но, т.к. технический анализ сродни статистике, данный показатель можно (и нужно) использовать в техническом анализе для обнаружения степени рассеяния цены анализируемого инструмента во времени. Обозначается греческим символом Сигма «σ».
Спасибо Карлам Гауссу и Пирсону за то, что мы имеем возможность пользоваться стандартным отклонением.
Используя стандартное отклонение в техническом анализе , мы превращаем этот «показатель рассеяния » в «индикатор волатильности «, сохраняя смысл, но меняя термины.
Что представляет собой стандартное отклонение
Но помимо промежуточных вспомогательных вычислений, стандартное отклонение вполне приемлемо для самостоятельного вычисления и применения в техническом анализе. Как отметил активный читатель нашего журнала burdock, «до сих пор не пойму, почему СКО не входит в набор стандартных индикаторов отечественных диллинговых центров «.
Действительно, стандартное отклонение может классическим и «чистым» способом измерить изменчивость инструмента . Но к сожалению, этот индикатор не так распространен в анализе ценных бумаг .
Применение стандартного отклонения
Вручную вычислить стандартное отклонение не очень интересно , но полезно для опыта. Стандартное отклонение можно выразить формулой STD=√[(∑(x-x ) 2)/n] , что звучит как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
Если количество элементов в выборке превышает 30, то знаменатель дроби под корнем принимает значение n-1. Иначе используется n.
Пошагово вычисление стандартного отклонения :
- вычисляем среднее арифметическое выборки данных
- отнимаем это среднее от каждого элемента выборки
- все полученные разницы возводим в квадрат
- суммируем все полученные квадраты
- делим полученную сумму на количество элементов в выборке (или на n-1, если n>30)
- вычисляем квадратный корень из полученного частного (именуемого дисперсией )